0x00 问题描述
Cart Pole 是一个倒立摆问题:一根杆子通过非驱动接头直立放置在小车上,小车沿着无摩擦的轨道移动。
目标是通过在小车上向左和向右施加力来平衡杆,坚持得越久越好。
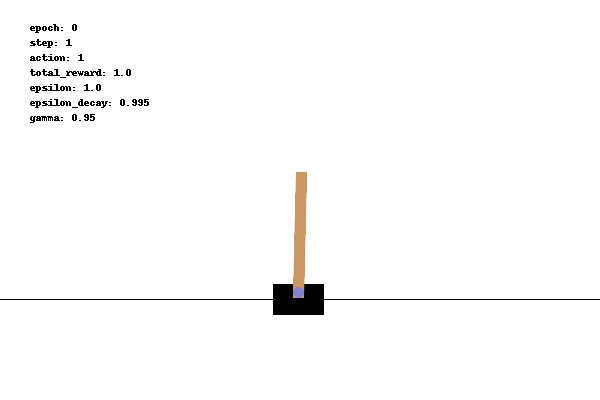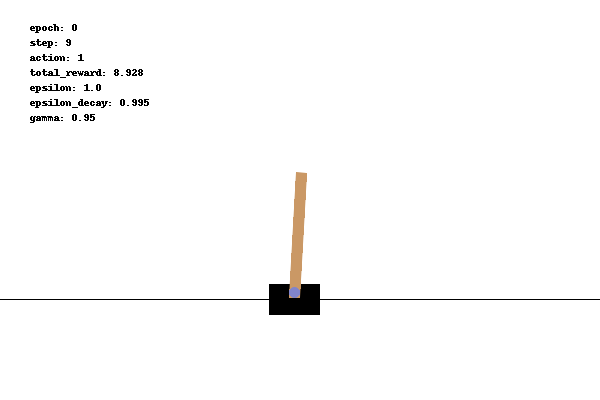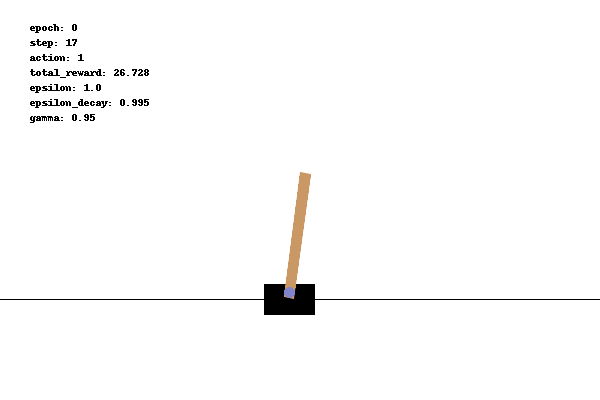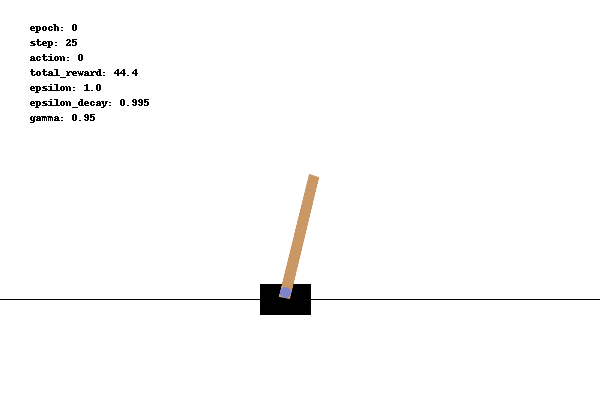
0x10 问题解读
从 Cart Pole 页面的描述中,我们可以得到不少关键信息:
0x11 环境说明

首先看到这个这个表,它的含义是:
- 在 python 通过以下语句可以创建 CartPole(版本 v1)的预设环境:
import gymnasiumenv = gymnasium.make("CartPole-v1")
- 而在这个预设环境中:
- 执行
env.action_space可以得到动作空间(Action Space)为Discrete(2) - 执行
env.observation_space可以得到观测空间(Observation Space)为Box([-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38], (4,), float32)
- 执行
对于 “环境”、“动作空间”、“观测空间” 等术语我们已经在第一节里面解释过,这里就不再赘述其含义了。
0x12 动作空间
Cart Pole 文档中给出的动作空间为:
- 动作 0: Push cart to the left (推动小车向左)
- 动作 1: Push cart to the right (推动小车向右)
与 env.action_space 得到值范围是一致的,这是两个离散动作(离散空间)。
0x13 观测空间
观测空间 observation_space 初始状态为: Box([-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38], (4,), float32)
因为使用了 Box 类型,显然这是一个连续空间,其含义为:
[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38]是观察空间中每个维度的最小值[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38]是观察空间中每个维度的最大值(4,)表示观察空间是一个四维的空间。这是一个元组,其中只有一个元素,即4,表明有 4 个独立的观察值。float32表示这些值是 32 位浮点数
结合 Cart Pole 文档给出的表格:
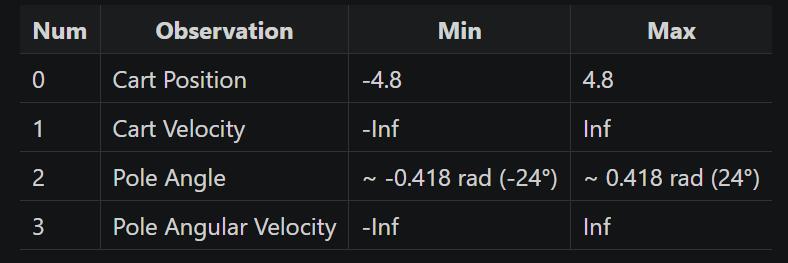
从表格可知,observation_space 的 4 个独立的观察值分别代表:
- 0: Cart Position: 小车位置,即 x 坐标轴的范围
- 1: Cart Velocity: 小车速度
- 2: Pole Angle: 极角,即杆子和垂直线之间的夹角
- 3: Pole Angular Velocity: 杆子绕其轴的角速度,即其倾斜速率的快慢
0x14 奖励
Cart Pole 的目标是尽可能长时间地保持杆子直立,因此在结束回合前,它的每一步都可以获得 +1 的奖励值。
在 v1 版本中,奖励的上限值为 500; v0 版本奖励的上限值为 200。
0x15 初始状态
初始状态中的每个参数均在 (-0.05, 0.05) 之间统一初始化。
0x16 回合终止
如果发生以下情况之一,则回合终止:
- 终止: 极角大于
±12° - 终止: 小车位置大于
±2.4(小车中心到达显示屏边缘) - 中止: 回合步数大于 500(v0 版本 为 200)
可以视 中止 条件就是成功完成挑战的条件,因为只有达到步数上限才能得到最大奖励
0x20 解题过程
0x21 初步分析
乍一看 Cart Pole 与上一节的 Acrobot 问题很相似:两者都属于连续状态空间、离散动作空间问题。
唯一区别是完成挑战的目标:
- Acrobot 成功挑战的目标是尽快完成特定任务(使杆子摆动到一定高度)
- Cart Pole 成功挑战的目标是尽可能长时间地保持杆子直立,直到达到步数上限(v1 版本为 500 步)
刚开始的时候,我并没有在意这个区别,毕竟 Cart Pole 累积越多步数、总奖励就会越高。于是我尝试直接使用 Acrobot 的代码 去求解 Cart Pole 。
但是在训练的过程中,我就发现了一个问题: 不论训练多久,智能体始终倾向于在 100 - 200 步左右提前终止挑战,而没有考虑最大步数(500)的情况。
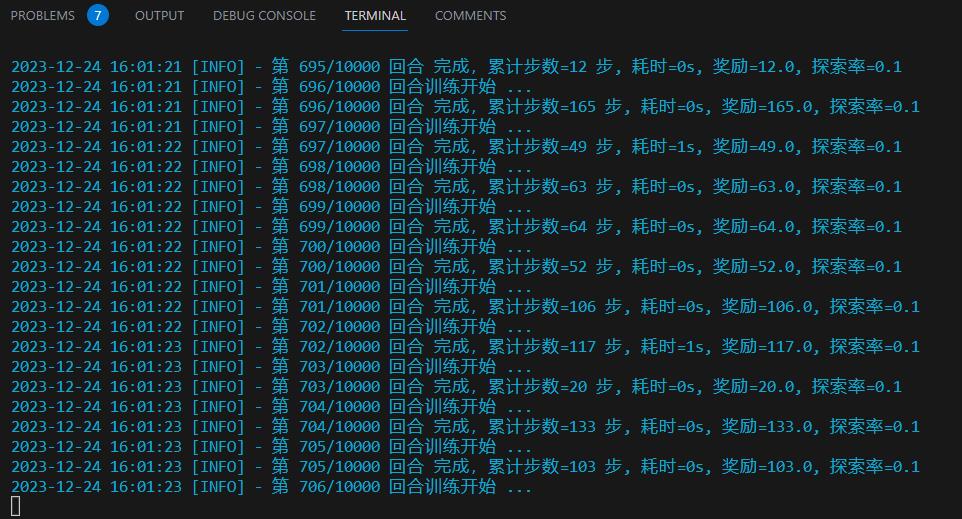
观察 tensorboard 的曲线,反映出的也是一样的情况:

0x22 尝试增加一次性奖励
其实这是和 DQN 算法特性有关,它通过学习一个价值函数来估计每个动作的期望回报,并利用这些信息来选择下一步动作。但是 DQN 本质是贪婪的(短视的)算法,它只注重短期的收益回报,当继续坚持的风险高于奖励的价值时,智能体就会倾向提前中止挑战。
简而言之,每一步 +1 的奖励,在 DQN 策略下不足以激励智能体完成更多的回合数。
于是我在 Acrobot 的代码 的基础上,进行 reward shaping(奖励重塑):
def exec_next_action(targs: TrainArgs, action, epoch=-1, step_counter=-1) :
next_raw_obs, reward, terminated, truncated, info = targs.env.step(action)
next_obs = to_tensor(next_raw_obs, targs)
done = terminated or truncated
# ---------- 修改的代码 ----------
# 当智能体以最大步数完成挑战时,获得一次性的大额额外奖励
if truncated :
reward += MAX_STEP
# -------------------------------
return (next_obs, reward, done)如代码所示,当智能体以最大步数完成挑战时,获得一次性的大额额外奖励 +500。
但是重新训练发现,情况依旧。
我观察了一下训练过程,智能体完成 500 步的回合数寥寥可数,也就是说这个大额奖励太遥远了,可能智能体压根就不知道有这个大额奖励的存在。
0x23 尝试增加持续激励
我突然联想到了在《猫和老鼠》中,Tom 诱捕 Jerry 的一幕:

太遥远的奖励智能体很难触达到,但是我可以每隔一定的步数,给智能体一个额外的 “糖果” 作为里程碑目标!
这样就就可起到一个持续激励的作用,智能体会更愿意获得 “糖果” 而坚持更多的步数。
于是我就设置了一个阶梯式的奖励机制:
# 每坚持 10 步,可以在原奖励基础上得到额外的 +10 奖励(额外小糖果,持续激励)
if step_counter % 10 == 0 :
reward += 10
# 每坚持 100 步,可以在原奖励基础上得到额外的 +100 奖励(额外大糖果,持续激励)
if step_counter % 100 == 0 :
reward += 100同时为了进一步鼓励智能体努力延长整个回合的持续步数,我修改了每一步固定的 +1 奖励,这个奖励会乘以一个递减因子,使得智能体在回合的后期、难以依赖步数增长获得更多奖励,只能通过 “糖果” 增加收益:
# 智能体每一步得到的奖励逐步递减,目的是使得智能体不要专注短期收益
increment_factor = 1 - step_counter / MAX_STEP # 递减因子 = 1 - 当前步数 / 步数上限
reward = reward * increment_factor完整的修改代码可以参考 02_Cart_Pole/train_DQN.py:
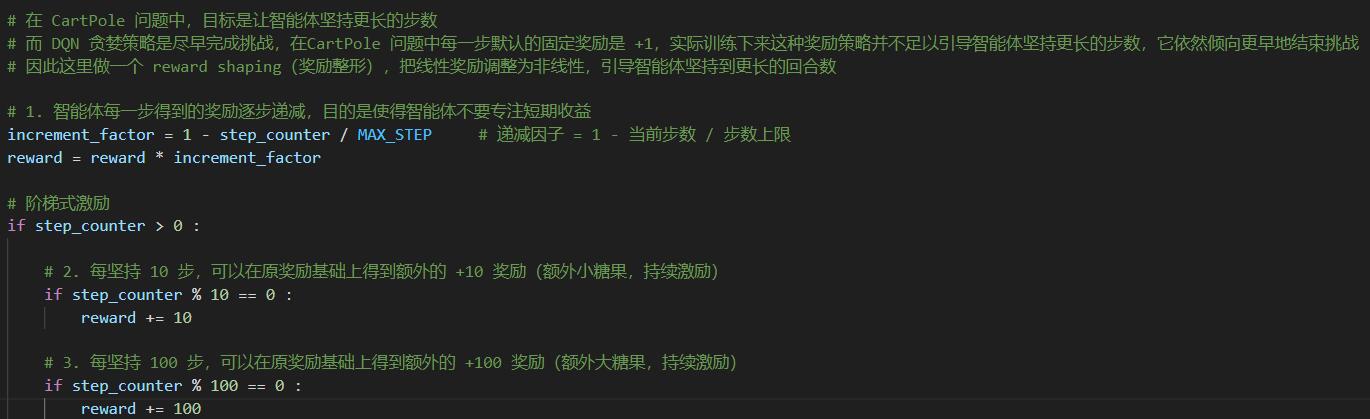
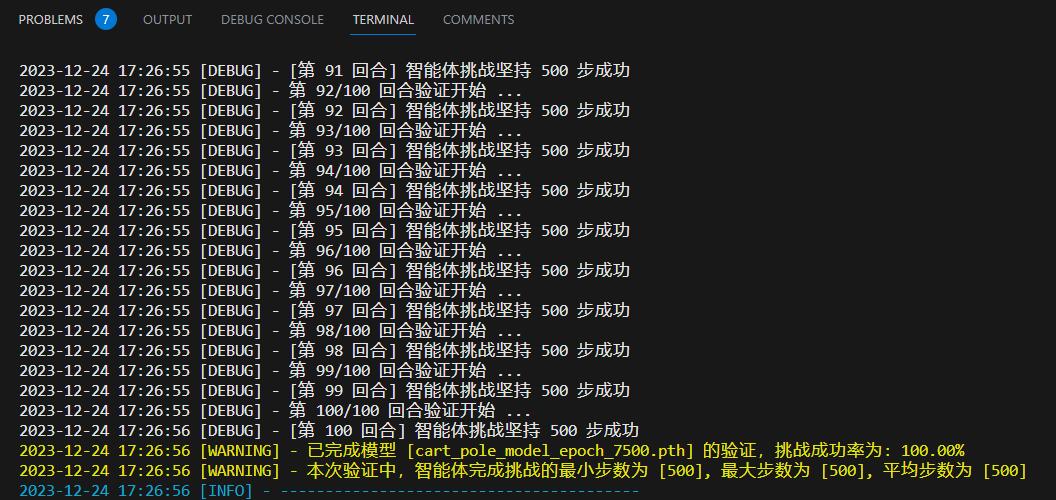
通过平衡短期和长远激励策略,智能体在训练到 7500 回合之后,可以 100% 以最大的步数完成挑战: