0x00 前言
Gymnasium (早期版本称为 Gym)是 OpenAI Gym 库的一个维护分支,它定义了强化学习环境的标准 API。
Gym 完全 python 化、界面简单,提供了一系列已经构建好的 RL 问题的标准环境,无需过多操心交互问题、只需要关注强化学习算法本身,故适合 RL 入门学习使用。
本笔记旨在记录使用 OpenAI Gym 平台进行强化学习实验时遇到的问题和总结的经验,希望能帮到刚入门的同学。
RL,即 Reinforcement Learning,强化学习
0x10 开发环境搭建
0x11 安装 conda(管理 python 虚拟环境)
由于 Gym 的 python 运行环境对依赖库的版本要求极严格(其实 RL 都有类似的问题,版本号很多时候都必须 ==),故如果和正在使用的 python 环境一起混用,往往因为已安装的库版本冲突、连 Gym 都安装不了。
因此为了避免麻烦,建议一开始就建议创建一个干净的 python 虚拟环境。
管理 python 虚拟环境有多种方式,这里推荐使用 conda 。
conda 有两个 release 版本: Anaconda 和 Miniconda,前者是全量安装,后者是最小化安装。都可以用,我选的是 Miniconda,没必要全量安装,用到时按需配就好。
conda 安装步骤如下:
- 去官网下载并安装 conda
- 把 conda 安装目录下的 Scripts 目录添加到 Path 环境变量,例如
S:\04_work\miniconda\Scripts - 根据你当前的终端执行对应的初始化命令,使其之后可以执行 conda 命令:
conda init powershell # win powershell
conda init bash # mac/Linux bash
conda init zsh # mac/Linux zsh
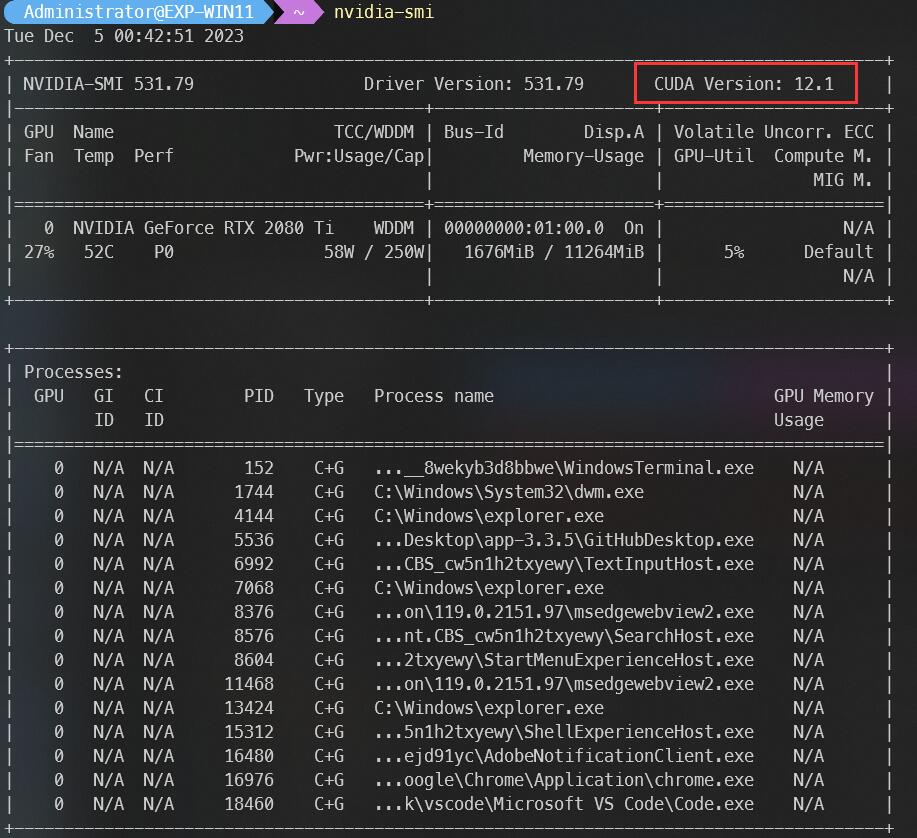
... ...- 如果使用 GPU 且是 N 卡,先执行命令
nvidia-smi查看 CUDA 版本:
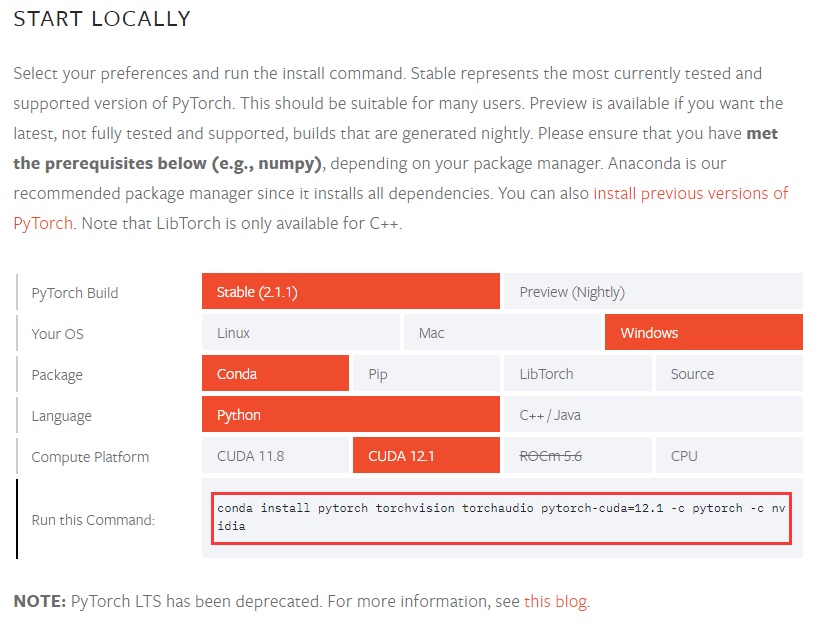
- 到 pytorch 官网,生成 RL 环境的安装命令(一般选择 OS 和 Compute Platform 即可),例如我的命令为:
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
- 最后执行生成的命令,使得 conda 可以在支持 CUDA 的 GPU 上运行 PyTorch,以便之后使用 Gym 进行模型的训练和推理。
0x12 安装 swig
在 OpenAI Gym 的某些环境中,可能需要调用用 C 或 C++ 编写的底层库。例如,一些仿真环境(如物理仿真)可能是用这些语言编写的。
此时需要 swig 支持,它可以把这些库接口转换为 Python 能够调用的格式,这样 Python 代码就可以与这些底层库交互。
对我们而言只需要安装到系统上就好:
- 去官网下载并安装 swig
- 把 swig 的安装目录添加到 Path 环境变量,例如
S:\04_work\swigwin-4.1.1
0x13 创建 Gym 虚拟环境
- 创建名为 RL_GYM 的 python3 虚拟环境:
conda create -n RL_GYM python=3.11.6 - 激活并切换到 RL_GYM 环境:
conda activate RL_GYM(每次退出终端后需要重新激活) - 创建
requirements.txt文件,内容如下:
gymnasium[all]
pyglet
tensorboardX- 安装 Gym 依赖:
python -m pip install -r requirements.txt
0x20 开始强化学习之前
0x21 什么是强化学习
强化学习是一种机器学习的方式,就像在学校学习一样。想象一下,如果你是一个机器人,你要学会如何做事情,但是没有老师直接告诉你每一步怎么做。你需要通过尝试和错误来学习。
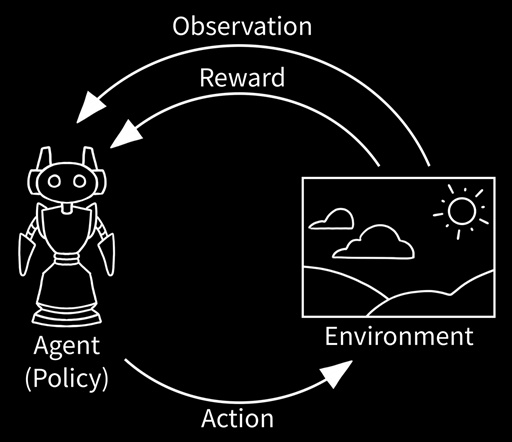
强化学习有几个核心概念:
- 环境:这就像是你学习的地方,比如学校或者体育馆。对于机器人来说,环境可能是一个游戏,或者是它要学习如何驾驶的道路。
- 训练:这就像你在学校里做练习和参加考试。机器人也是通过在环境中尝试不同的动作来学习。每当它做了一个动作,环境就会给它一个积分或者反馈,告诉它这个动作做得好不好。
- 奖励:就像你在考试中得到好成绩后得到奖励一样,机器人在做对了事情时也会得到积分或奖励。机器人的目标是获取尽可能多的积分或奖励。
举个例子,如果机器人在一个游戏中,每次避开障碍物就能得到积分,那么它就会学习怎样更好地避开障碍物。它通过不断尝试,从错误中学习,最终找到最好的方法来完成任务。
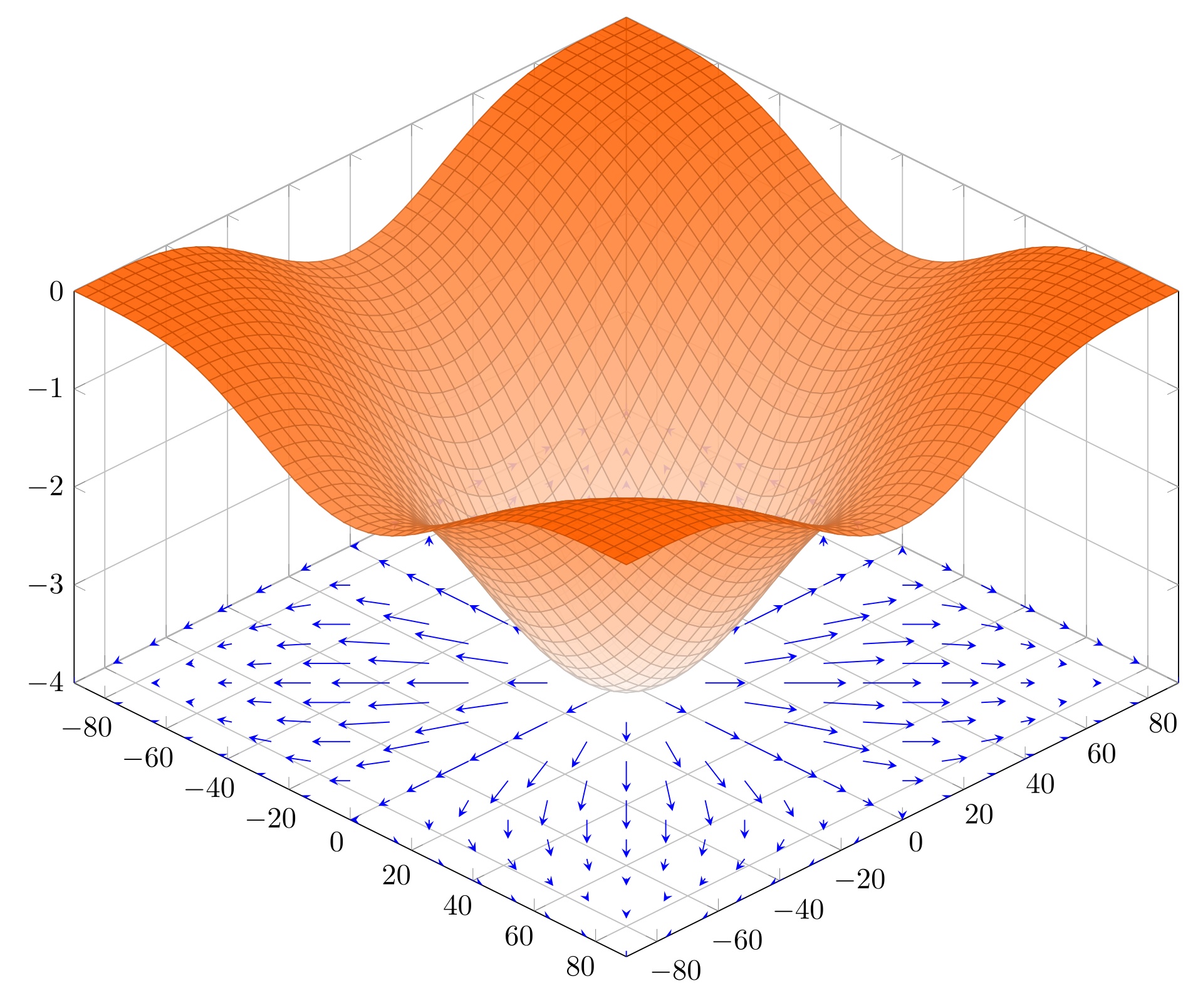
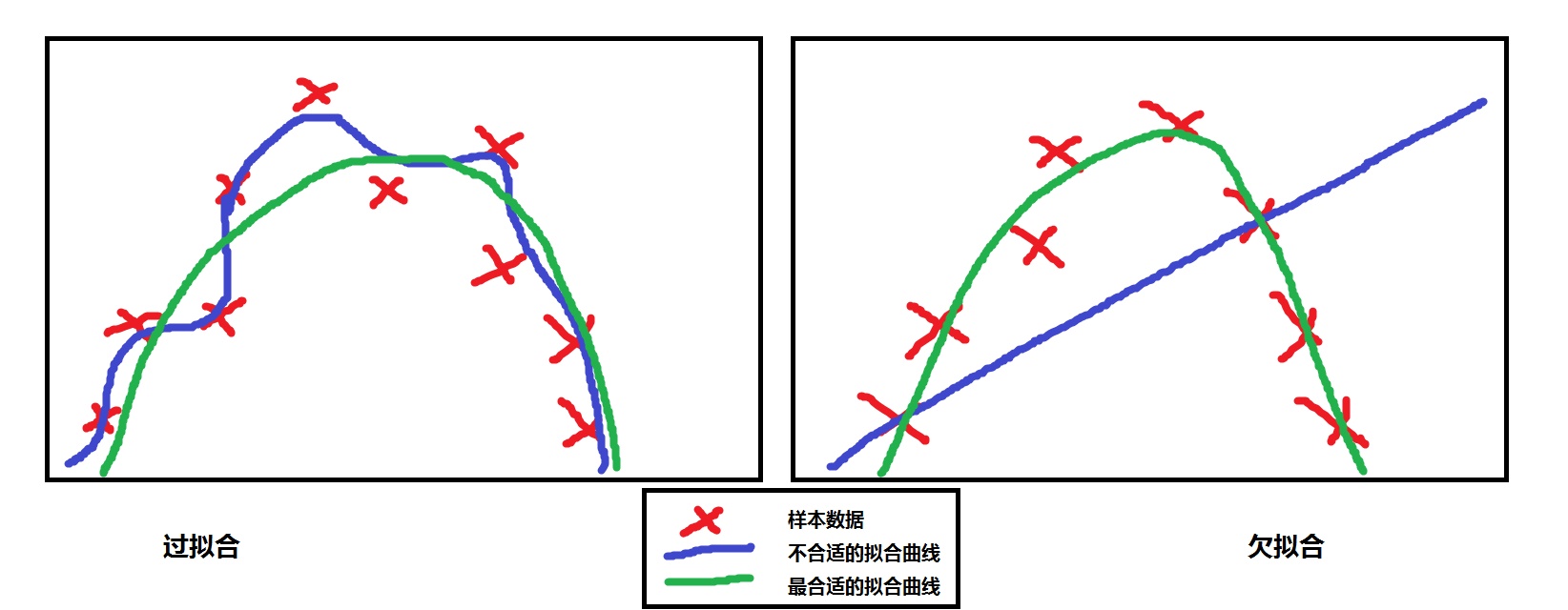
其实强化学习过程,和数学上的 “将离散点拟合成曲线” 的过程很相似,前者是为了找到最优的算法或策略、后者则是为了构建一个拟合度最好的曲线:
0x22 基本概念
在后续 Gym 课程的学习中,你将会逐步接触到这些基础概念,故我先在这里解释一下。
如果现在没看懂什么意思也不要紧,后面结合代码或公式会更容易理解,这里先留个印象,如若碰到了,可以回来这里找。
在每一节 Gym 内容中,你都会接触到这些概念:
| 概念 | Concept | 含义 | 类比解释 |
|---|---|---|---|
| 环境 | Environment | 代表要解决的任务或问题 | 比如在一个电脑游戏中,环境就是整个游戏的世界。 |
| 观测 | Observation | 代表环境的当前状态 | 好比玩家在这个游戏世界里看到的东西,它告诉玩家现在世界的情况是怎样的。 |
| 观测空间 | Observation Space | 代表可以感知环境的状态范围 | 比如玩家可以在游戏世界里面看到自己的 HP/SP、角色等级等,但是无法看到别人身上的金钱、道具等。 |
| 动作 | Action | 代表在某状态下执行的动作(执行动作后会改变当前环境) | 在了解游戏世界当前的情况后,玩家决定采取的行为,移动、跳跃、攻击等。 |
| 动作空间 | Action Space | 代表在某状态下所有可能执行的动作范围 | 玩家只能在游戏允许的范围内选择动作执行,例如可以向左走、向右跳,但是不允许向上飞。 |
| 奖励 | Reward | 当环境转移到新状态时给予的奖励 | 好比当玩家执行动作对游戏进行干涉、游戏环境发生改变后反馈的结果,可以是正反馈也可以是负反馈,例如打怪升级、死亡掉装备等。 |
“观测空间” 有时也称作 “状态空间”
在训练神经网络模型时,你将会接触到这些常用概念:
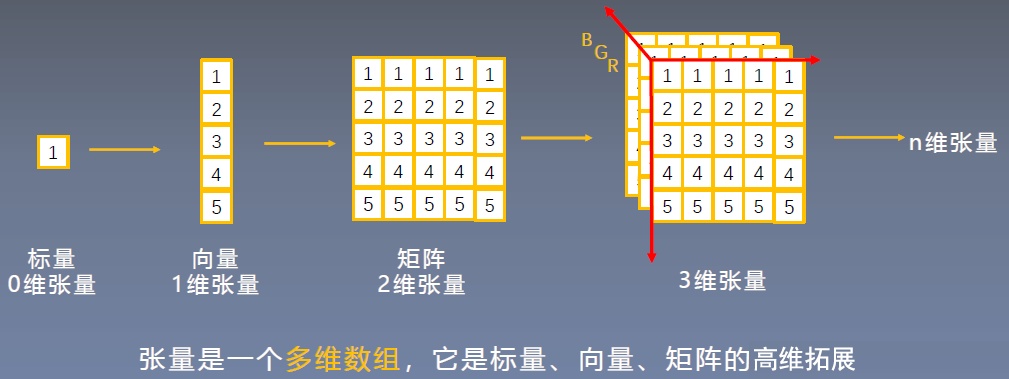
| 张量(tensor) | 在计算机科学中,张量通常可以看作是一种多维数组,可以把它想象成一个可以存储数字的多维格子 |
|---|---|
| 零维张量 | 这就是一个普通的数字,也称为标量(Scalar)。 |
| 一维张量 | 这是一个数字的线性数组,也就是数学中的向量(Vector)。比如,[1, 2, 3] 是一个一维张量。 |
| 二维张量 | 这是数字的一个二维数组,也就是数学中的矩阵(Matrix)。例如,[[1, 2, 3], [4, 5, 6]] 是一个二维张量。 |
| 三维及以上张量 | 当数组有三个或更多维度时,就形成了三维或更高维度的张量。这些通常难以用传统的方式可视化,但在机器学习中非常常见。比如,一个彩色图像可以表示为一个三维张量,其中维度分别代表高度、宽度和颜色通道。 |
| 概念 | Concept | 含义 | 类比解释 |
|---|---|---|---|
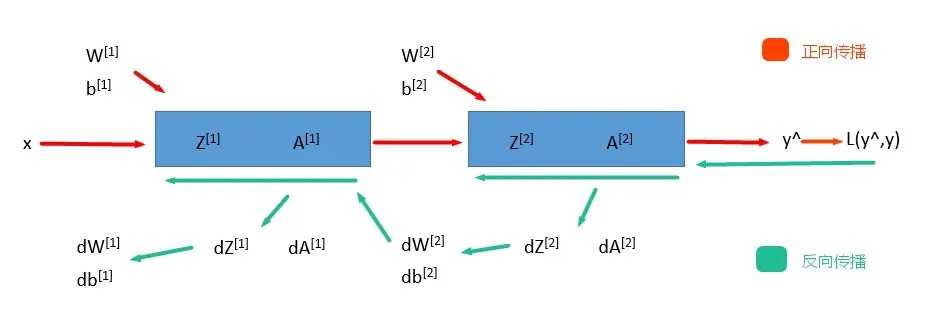
| 正向传播 | Forward Propagation | 就是从输入层 input,经过一层层的 layer,不断计算每一层的 z 和 a,最后得到输出 y^ 的过程。 |
就像解数学题时、从问题到计算答案的过程。 |
| 损失 | loss | 计算出了 y^,就可以根据它和真实值 y 的差距来计算损失 loss = L(y^,y)。 |
就像考试中犯的错误,损失越小,意味着你的模型越准确。 |
| 反向传播 | Backward Propagation | 就是根据损失函数 L(y^,y) 来反方向地计算每一层的 z、a、w、b的偏导数(梯度),从而更新网络参数的过程。 |
类比就像当我们计算出结果后、重新验算的过程,它帮助我们了解在哪里可能算错了,然后告诉我们怎样调整计算步骤来得到更准确的答案。 |
每经过一次正向传播和反向传播之后,神经网络的参数就更新一次,然后用新的参数再次循环上面的过程。这就是神经网络训练的整个过程。
在优化模型参数时,你将会接触到这些常用概念:
| 概念 | Concept | 含义 | 类比解释 |
|---|---|---|---|
| 梯度 | Gradient | 在数学中,梯度是一个函数在某一点的斜率或变化率。在多维空间中,梯度是一个向量,指出函数在每个方向上的斜率。而在神经网络中,梯度指的是损失函数(这是一个衡量模型预测准确性的函数)相对于模型参数(如权重和偏置)的斜率。它告诉我们如何调整参数以减少损失,即提高模型的准确性。 | - |
| 梯度下降 | Gradient Descent | 这是一种优化算法,用于调整神经网络的参数,以最小化损失函数。它的工作原理是计算损失函数的梯度,然后沿着梯度下降的方向调整参数。 | 这就像是下山,你总是选择坡度最陡的方向往下走,以最快的速度到达山谷(即损失最小的点)。 |
| 梯度爆炸 | Gradient Explosion | 是指在训练过程中梯度变得异常大的现象。这通常发生在深层网络中,特别是当网络层较多时。当梯度爆炸发生时,模型的权重会进行极大的更新,导致模型无法学习,或者学习得非常不稳定。 | 这就好比下山时不是走路,而是滚下去,可能会失控并偏离正确的路径。 |
| 梯度裁剪 | Gradient Clipping | 这是解决梯度爆炸问题的技术,它通过设定一个阈值来限制梯度的最大值。 | 这就像是说:“如果梯度太大了,就把它限制在这个范围内。”这有助于稳定训练过程并防止数值计算错误。 |
| 梯度消失 | Gradient Vanishing | 它是指在神经网络的训练过程中,梯度的大小逐渐变小,直到几乎为零。在深层神经网络中,梯度必须通过多个层进行反向传播。每经过一层,梯度都可能变小。因此,对于网络中靠近输入层的层,梯度可能变得非常小甚至消失,此时权重更新变得非常微小,这使得网络很难学习和改进。 | - |
| 激活函数 ReLU | Rectified Linear Unit | 一种在神经网络中常用的非线性函数,其数学表达式为 f(x) = max(0, x),这意味着,如果输入 x 为正,则输出 x;如果 x 为负,则输出 0。因此 ReLU 函数在正数区域的梯度恒为 1,这有助于缓解梯度消失问题。 |
- |